Out-of-order and super scalar
Out-of-order
We build two buffers to accommodate two different kinds of instructions. Even when the commit of instructions is stuck by data memory temporarily, the pipeline is not blocked until the buffers are full. The problem now is to make more instructions pass the ALU module to reach either buffer.
In last section, it is assumed that when a LDR instruction is accepted by the “mmbuf” buffer, a blacklist of its Rd is used to check Rs or Rd of the following instructions. A LDR instuction reserves its Rd for its future fetching. The following instruction is not allowed to call this register as input register Rs because it is undertermined and could not write to it as destination register Rd until the LDR has been done.
When multiple LDR instructions are stored in the “mmbuf” buffer, it is convenient to have a 32-bit variable, each bit of which is to denote its register is a reservation. Multiple expressions of (1’b1«Rd ) are ORed to constitute the blacklists of Rs or Rd. If two LDR instructions have the same Rd, its destination register is tagged only once.
When the next instruction has a Rs or Rd, which is happened to be one of blacklists, this next one is not possibile to pass the ALU module and reach destination buffers. The method “out-of-order” will suggest to hold this one and consider its closest next instruction.
Let’s take an example. When two LDR instructions are cached in the “mmbuf” buffer, their Rds, which are R1 and R2, constitute the blacklists: rs_list and rd_list. The current instruction is one “OP” instruction whose Rs’s are R2 and R3, Rd is R4. Because one of its Rs is matched with rs_list, this “OP” instruction is not possibile to be issued. So, let’s check its closest next one.
The current instruction is skipped for this cycle, which means it will be executed in the future cycles and its operand registers Rs should be kept untouched by the following ones, the destination register Rd should not be called by the following ones. We could carry out this intention by appendding rs_list and rd_list.
The example current “OP” instuction will append its Rd:R4 to rs_list for the following ones, because R4 will have a future change as a “LDR” instruction does. It will append its Rs’s: R2 and R3 and Rd: R4 to rd_list, because it should be sure that its operands and destination are kept untouched and when this “OP” instruction is executed in the future, it will have its registers untouched.
To append the blacklists of Rs and Rd will make the following instructions face more strict limitation. It will make sure the skipped instruction is not harmed by this out-of-order method. It is necessary to make every instructions face an evaluation of incremental blacklists of Rs and Rd.
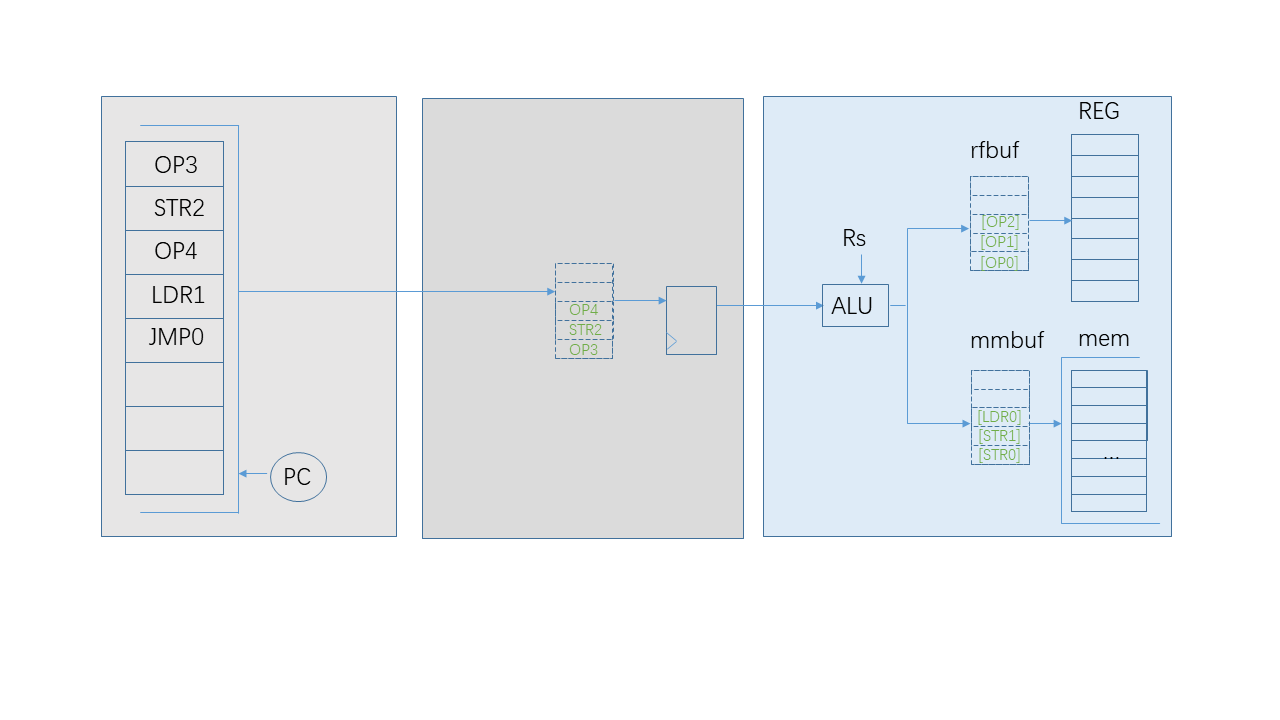
A buffer is introduced in the stage 2 to keep candidate instructions. When an instruction is skipped, it will stay in this buffer and continue to be evaluated in the next cycle until it leaves the stage 2. When this buffer has spare seats, instructions should be fetched to fill the buffer full until a “JMP” instruction is encountered. A “JMP” instruction represents abandoning the following instructions and turn to other new instructions. It is not permitted to make the following instructions skip a “JMP” instruction. When this “JMP” instruction leaves the buffer, the successive instructions are allowed to enter the buffer, whether which are from a new address or the very next position.
If only one ALU module exists, only one instruction is chose to be executed in every cycle. Each of living elements of the buffer is evaluated to choose this only one. The very first candidate has loose Rs and Rd blacklists. If it is the winner, the evaluation is over. If it is a loser, it will append its registers to the two blacklists to make sure its own future execution is protected. It is an iteration of generating new blacklists and applying them.
The blacklist is not the only factor to choose. If one of the two destination buffer is full, no more OP or LSU instruction is needed and the qualified one should be abandoned. If one of LSU instructions is evaluated to be stayed in the buffer, all of the following LSU instructions have to be stayed because LSU instructions should be kept in-order strictly. No skipping is happened between LSU instructions.
That is how I deal with the out-of-order method. Firstly, get a list of candidate instructions. Prepare the basic blacklists from the “mmbuf” buffer. From the first one of candidates, evaluate its qualification and generate new blacklists. Then, the next until all is evaluated.
Super scalar
Skipping unqualified instructions will make full use of one ALU module. This ALU will always have one instruction to process. But that is not enough. We think there are more than 1 instruction ready. Why not more than 1 ALU modules to process multiple instructions simultaneously?
That is the method of “super scalar”. From the candidate instructions buffer, multiple winners pass their respective ALU module and are accepted by the buffers which they belong to. This method will make more instructions reach the destination buffers simultaneously.
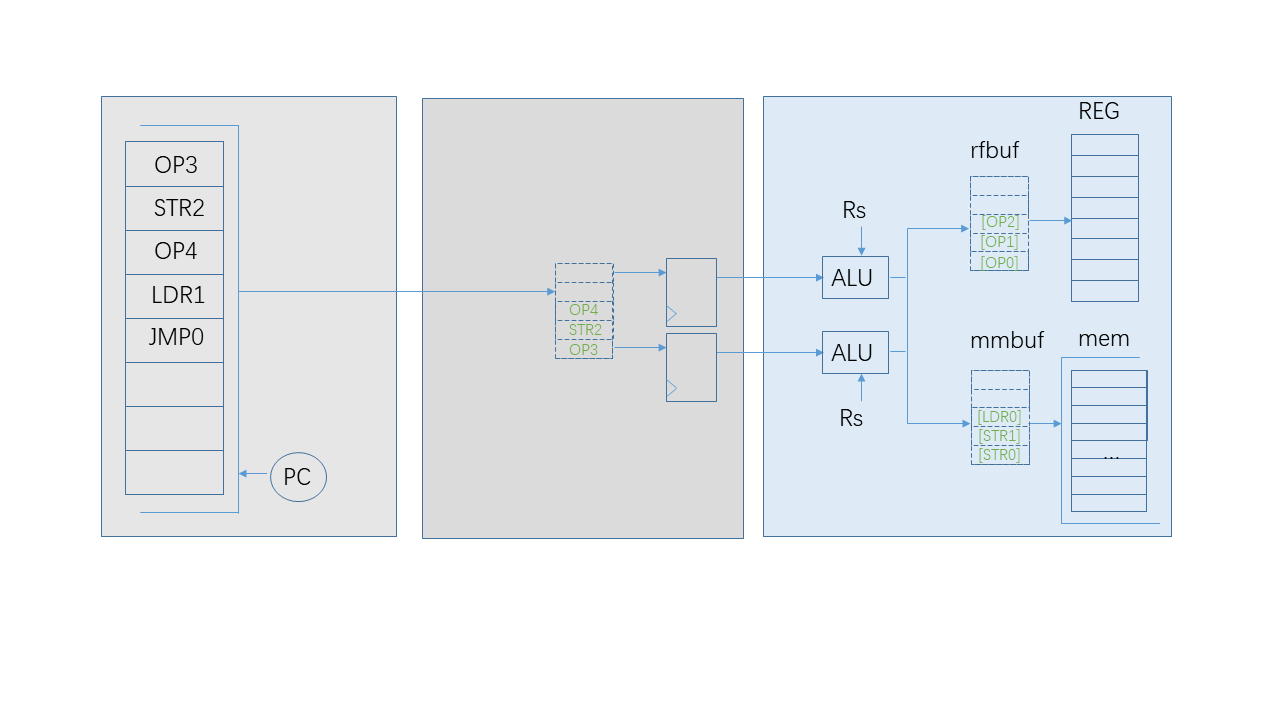
Let’s take the example to explain how to append blacklists when dealing with multiple winners. When two LDR instructions are cached in the “mmbuf” buffer, their Rds, which are R1 and R2, constitute the blacklists: rs_list and rd_list. The current instruction is one “OP” instruction whose Rs’s are R3 and R4, Rd is R5. This instruction is a winner because its Rs’s and Rd are clear to blacklists.
Its Rs’s will be called when it passes its ALU module. There is no need to append its Rs’s to rd_list. Its Rs’s have no effect on blacklists. How about Rd ? Rd means a change of some register. This instruction gives a future change of Rd and the next winner, which will be executed in the same cycle, could not call this register as an operand because the result is on the way to the buffer. So, the Rd of the current winner could be appended to rs_list. The Rd has no effect on rd_list, which means the following winner could have the right to write the same register.
Based on incremental blacklists, every winner could skip its older instructions and have its own ALU module to reach destination buffers.